Problem Description
I am unable to reach http://mail.ctwug.za.net, I get the following:
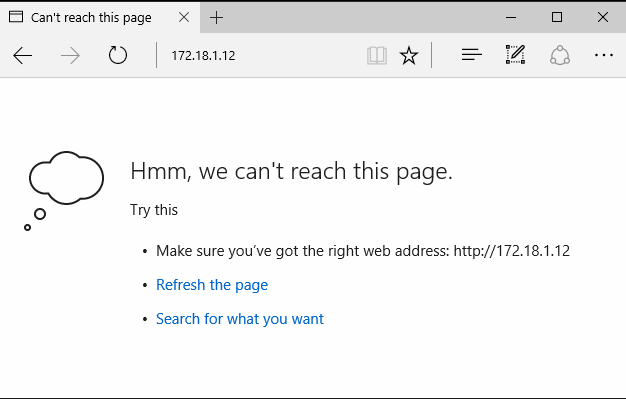
The traceroute to this reveals:
Tracing route to 172.18.1.12 over a maximum of 30 hops
1 <1 ms <1 ms <1 ms 192.168.0.1
2 <1 ms <1 ms <1 ms 172.26.65.254
3 <1 ms <1 ms <1 ms 172.26.65.251
4 6 ms 21 ms 17 ms 172.18.10.77
5 20 ms 3 ms 4 ms 172.18.10.6
6 9 ms 43 ms 54 ms 172.18.10.66
7 18 ms 13 ms 34 ms 172.18.239.9
8 26 ms 29 ms 19 ms 172.18.239.25
9 56 ms 8 ms 8 ms 172.18.239.253
10 * * * Request timed out.
…
30 * * * Request timed out.
Trace complete.
If I add a static route to my core 172.18.1.12 --> 172.26.65.253 (ironman link)
and a static route on ironman rb - 172.18.1.12 --> 172.18.115.189 (ironman rb)
I then am able to traceroute to the ip:
Tracing route to 172.18.1.12 over a maximum of 30 hops
1 <1 ms <1 ms <1 ms rbhome.mbd.za.net [192.168.0.1]
2 <1 ms <1 ms <1 ms 172.26.65.254
3 <1 ms <1 ms <1 ms 172.26.65.253
4 9 ms 5 ms 2 ms 172.18.115.189
5 6 ms 5 ms 5 ms 172.18.115.254
6 12 ms 6 ms 6 ms 172.18.115.180
7 53 ms 26 ms 28 ms 172.18.44.238
8 16 ms 8 ms 23 ms 172.18.44.252
9 13 ms 18 ms 14 ms 172.18.255.97
10 13 ms 13 ms 21 ms 172.18.110.221
11 14 ms 15 ms 30 ms 172.18.255.189
12 33 ms 22 ms 27 ms 172.18.248.194
13 29 ms 36 ms 34 ms 172.18.252.166
14 41 ms 36 ms 24 ms 172.18.60.233
15 194 ms 183 ms 169 ms 172.18.1.137
16 184 ms 170 ms 189 ms 172.18.1.12
Trace complete.
Now if I browse to http://mail.ctwug.za.net:
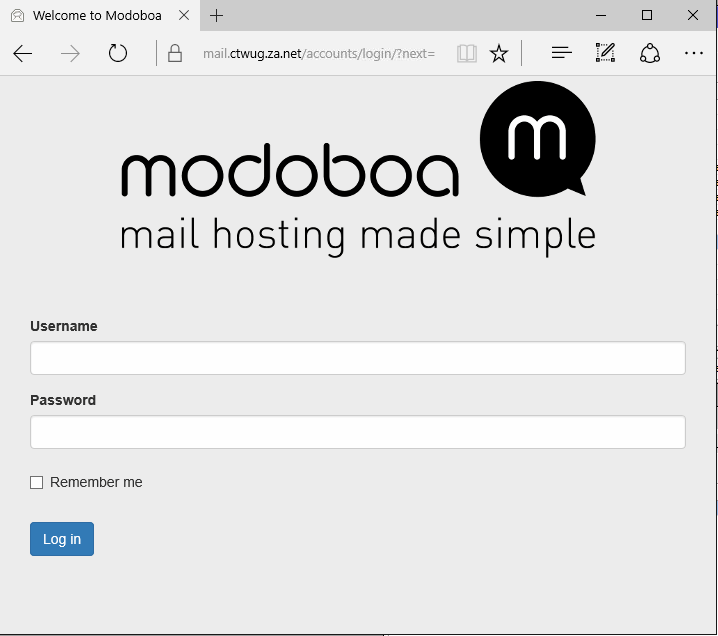
It is when routed via wugpi.km.ctwug.za.net (@spin) that I cannot reach the mail server, often WinD & Forum also does not work.
Your details
Node:
PC IP: 172.26.65.24
RB IP: 172.26.65.254
RB has ctwug/ctwug login?: yes
TRACERT
On command line run these and paste output here.
tracert 172.18.1.1
Tracing route to 172.18.1.1 over a maximum of 30 hops
1 <1 ms <1 ms <1 ms 192.168.0.1
2 <1 ms <1 ms <1 ms 172.26.65.254
3 <1 ms <1 ms <1 ms 172.26.65.253
4 6 ms 8 ms 2 ms 172.18.115.189
5 2 ms 1 ms 3 ms 172.18.115.246
6 7 ms 9 ms 5 ms 172.18.72.33
7 6 ms 5 ms 6 ms 172.18.72.4
8 8 ms 10 ms 18 ms 172.18.72.38
9 27 ms 13 ms 10 ms 172.18.1.1
Trace complete.
tracert 172.18.1.11
Tracing route to 172.18.1.11 over a maximum of 30 hops
1 <1 ms <1 ms <1 ms 192.168.0.1
2 <1 ms <1 ms <1 ms 172.26.65.254
3 <1 ms <1 ms <1 ms 172.26.65.251
4 6 ms 21 ms 17 ms 172.18.10.77
5 20 ms 3 ms 4 ms 172.18.10.6
6 9 ms 43 ms 54 ms 172.18.10.66
7 18 ms 13 ms 34 ms 172.18.239.9
8 26 ms 29 ms 19 ms 172.18.239.25
9 56 ms 8 ms 8 ms 172.18.239.253
10 * * * Request timed out.
Trace complete.
tracert 172.18.1.5
Tracing route to 172.18.1.5 over a maximum of 30 hops
1 <1 ms <1 ms <1 ms 192.168.0.1
2 172.26.65.254 reports: Destination net unreachable.
Trace complete.
172.18.1.5 is not in the routes
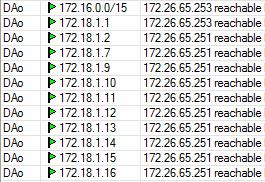
tracert 8.8.8.8
NSLOOKUP
On the command line run these and paste output here.
nslookup www.ctwug.za.net 172.18.1.1
nslookup www.ctwug.za.net 172.18.1.1
Server: UnKnown
Address: 172.18.1.1
Non-authoritative answer:
Name: obliquity.ctwug.za.net
Address: 192.121.166.59
Aliases: www.ctwug.za.net
nslookup www.ctwug.za.net
nslookup www.ctwug.za.net
Server: rbhome.mbd.za.net
Address: 192.168.0.1
Non-authoritative answer:
Name: obliquity.ctwug.za.net
Address: 192.121.166.59
Aliases: www.ctwug.za.net
